Goroutines: o padrão Worker Pool
O primeiro post de uma série sobre concorrência em Go — o que é um worker pool, por que ele protege contra goroutine leaks sob carga, seus trade-offs, e um exemplo executável com graceful shutdown.
Também disponível em English
E aí, pessoal! Esse é o primeiro post de uma série que estou animado para compartilhar sobre modelos de concorrência em Go. Para começar, escolhi um modelo conhecido como Worker Pool. Mas o que exatamente é um worker pool?
Basicamente, é um padrão em que um conjunto fixo de goroutines — também chamadas de workers — fica aguardando para receber tarefas e executá-las. Esse modelo traz várias vantagens e desvantagens, mas antes de entrarmos nelas, vamos visualizar como ele funciona.
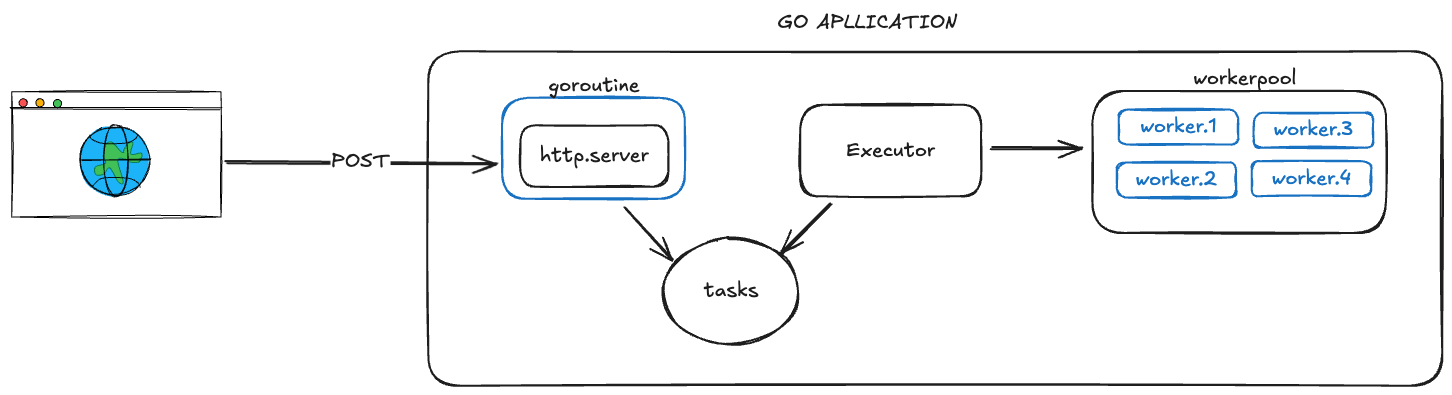
Como funciona
Neste exemplo básico, temos uma aplicação web em Go que implementa um worker pool. Quando alguém chama a aplicação, o nosso software não executa a tarefa de imediato. Em vez disso, ele guarda a tarefa em uma fila e retorna uma resposta ao usuário. Enquanto isso, em outra goroutine, os workers — atuando como consumidores — ficam escutando novas tarefas na fila e as processam conforme há capacidade disponível.
Benefícios de um worker pool
E qual é o benefício desse modelo? Uma das maiores vantagens é prevenir um goroutine leak. Imagine que estamos operando com uma quantidade limitada de RAM/CPU e um RPS baixo (requisições por segundo), digamos 30 RPS. Se cada tarefa leva cerca de 20 segundos para processar, teríamos no máximo uns 600 goroutines abertas simultaneamente, o que é gerenciável e não sobrecarregaria muito a nossa infraestrutura.
Agora suponha que haja um pico de uso e o nosso RPS suba para 60. Estaríamos olhando para no mínimo 1200 goroutines processando ao mesmo tempo. Isso pode se tornar insustentável em algum momento. O modelo de worker pool resolve isso de forma elegante, porque nos permite definir uma capacidade fixa de processamento. Assim, em vez de lidar com um goroutine leak nos horários de pico, a aplicação simplesmente fica mais lenta. Essa contrapressão dispara os nossos alertas, indicando que precisamos aumentar a capacidade do container e o número de workers.
Desvantagens de um worker pool
Claro, nada em software é perfeito. Se você leu até aqui, talvez já tenha pensado em algumas desvantagens — como o risco de dimensionar o pool de forma incorreta, ficando consistentemente abaixo do volume de tarefas. Isso tornaria o processamento mais lento do que simplesmente criar uma goroutine por tarefa.
Outro ponto importante é como construímos a fila de tarefas. Em cenários de processamento crítico, podemos precisar de uma forma de persistir as tarefas para que não se percam caso a aplicação caia. E há o desafio comum de concorrência de monitorar o estado de execução dessas tarefas. Um código bem estruturado e com logs bem definidos ajuda bastante aqui, mas ainda vale a discussão.
Hora de codar
Chega de conversa — vamos montar um pequeno exemplo para brincar. Começamos pelas structs que fazem o worker pool funcionar. Primeiro, o Worker:
type Worker struct {
ID int
TaskQueue chan Task
}Nosso worker tem dois campos: um ID para identificação e um canal no qual ele escuta novas tarefas para processar.
type WorkerPool struct {
Workers []*Worker
TaskQueue chan Task
}
type Task struct {
ID string
}Em seguida criamos o WorkerPool, que gerencia os workers e usa o canal de tarefas para notificá-los, junto com uma struct Task simples.
Depois disso, uma função que constrói o pool:
func NewWorkerPool(numWorkers int, wg *sync.WaitGroup) *WorkerPool {
taskQueue := make(chan Task, 1000) // um canal com buffer
pool := &WorkerPool{
Workers: make([]*Worker, numWorkers),
TaskQueue: taskQueue,
}
for i := 0; i < numWorkers; i++ {
wg.Add(1)
pool.Workers[i] = NewWorker(i+1, wg, taskQueue)
}
return pool
}Essa função recebe o número de workers que precisamos e cria um taskQueue com buffer. O que significa esse 1000? É o número máximo de tarefas que o canal consegue armazenar. Se ultrapassarmos esse limite, o canal não dá erro — quem envia simplesmente bloqueia até que haja espaço livre, permitindo que os workers continuem processando.
Agora vamos escrever o NewWorker:
func NewWorker(id int, wg *sync.WaitGroup, taskQueue chan Task) *Worker {
worker := &Worker{
ID: id,
TaskQueue: taskQueue,
}
go worker.start(wg)
return worker
}
func (w *Worker) start(wg *sync.WaitGroup) {
defer wg.Done()
for task := range w.TaskQueue {
fmt.Printf("Worker %d processando a task ID %s\n", w.ID, task.ID)
time.Sleep(10 * time.Second)
fmt.Printf("Worker %d finalizou a task ID %s\n", w.ID, task.ID)
}
}O NewWorker cria um worker a partir dos atributos recebidos — o ID e o canal de tarefas — e chama .start() para colocá-lo para trabalhar. O método start itera sobre o canal com range, processando cada tarefa que chega, e encerra de forma limpa assim que o canal é fechado.
Para deixar isso funcional, adicionamos um handler que empurra novas tarefas para o canal, que os workers então processam.
var pool *WorkerPool
func main() {
numWorkers := 4
wg := &sync.WaitGroup{}
pool = NewWorkerPool(numWorkers, wg)
stop := make(chan os.Signal, 1)
signal.Notify(stop, os.Interrupt, syscall.SIGTERM)
server := &http.Server{Addr: ":8081"}
http.HandleFunc("GET /task/{id}", taskHandler)
go func() {
fmt.Println("Servidor rodando em :8081")
if err := server.ListenAndServe(); err != http.ErrServerClosed {
fmt.Printf("erro no servidor: %v\n", err)
}
}()
<-stop
server.Shutdown(context.Background())
close(pool.TaskQueue)
wg.Wait()
fmt.Println("Shutdown completo")
}
func taskHandler(w http.ResponseWriter, r *http.Request) {
taskID := r.PathValue("id")
pool.TaskQueue <- Task{ID: taskID}
fmt.Fprintf(w, "Task ID %s adicionada\n", taskID)
}Repare no canal stop, que escuta sinais de encerramento. Quando um chega, paramos o servidor, fechamos o canal de tarefas para não aceitar novas, e esperamos os workers terminarem o que ainda estão processando. Só então a aplicação encerra — esse é o nosso graceful shutdown.
Rode a aplicação e faça uma requisição GET para o endpoint:
curl http://localhost:8081/task/1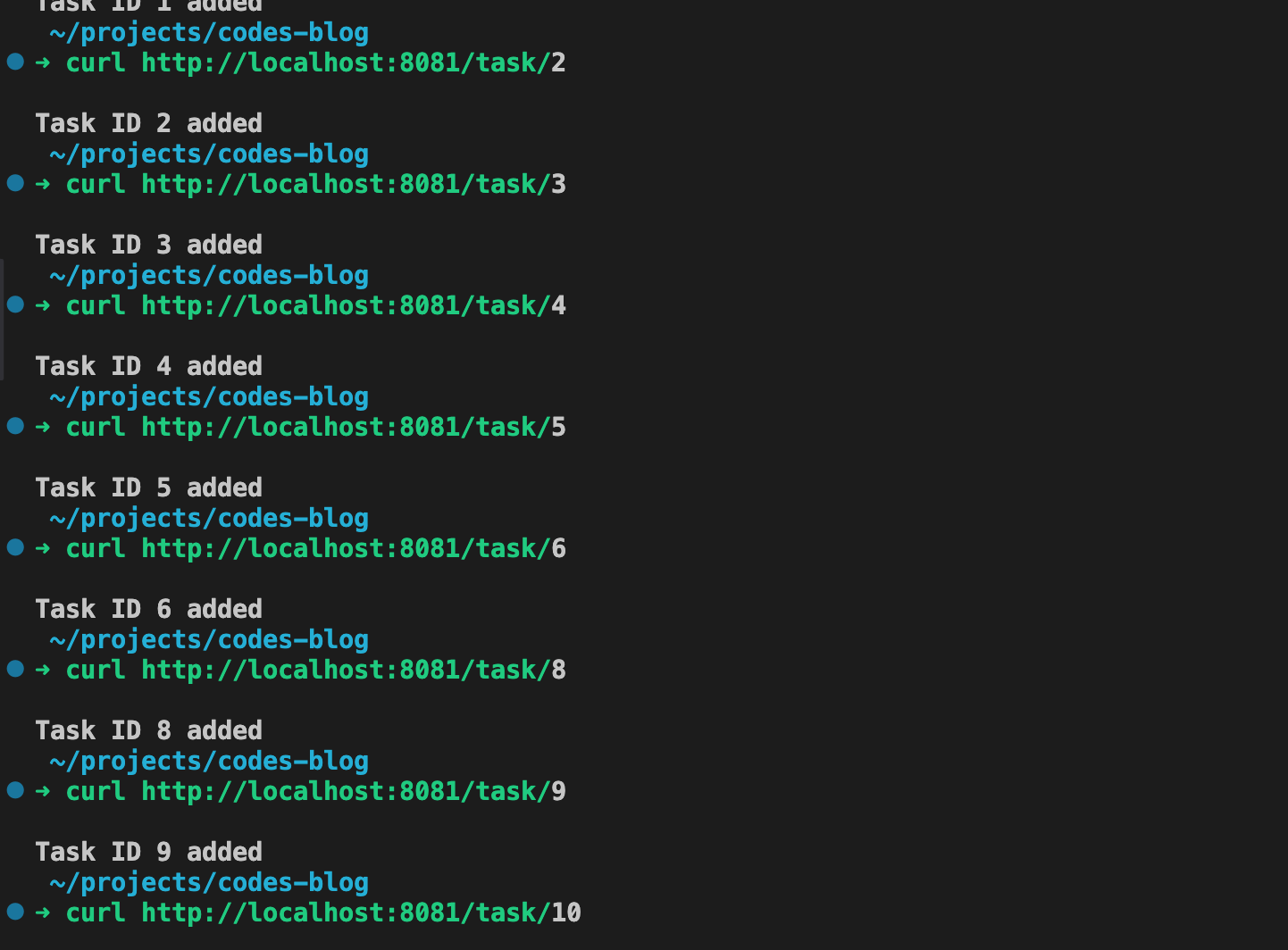
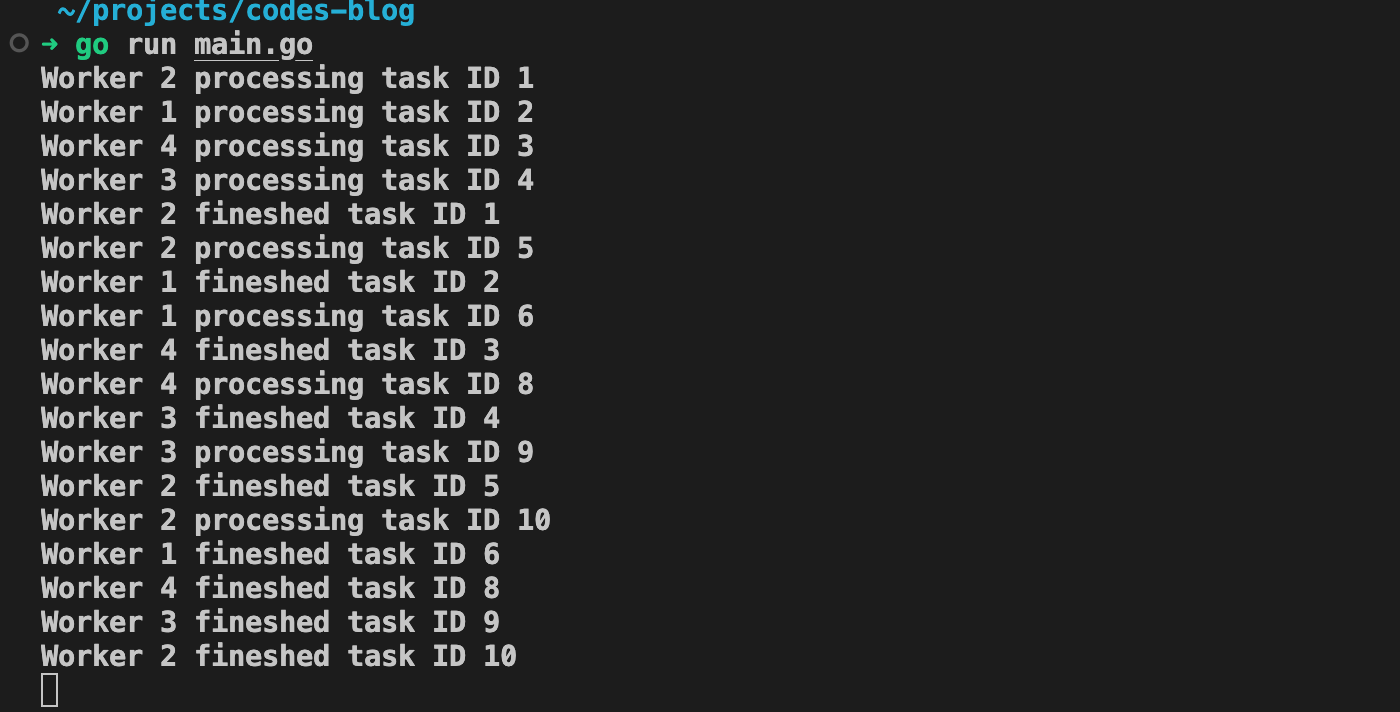
E é isso — o nosso worker pool está no ar processando tarefas. Como dá para ver, não há uma ordem fixa de qual worker pega qual tarefa; na verdade, o Worker 2 pega a primeira.
Espero que tenham curtido o post! Vamos continuar explorando Go e suas possibilidades.